arXiv 2026
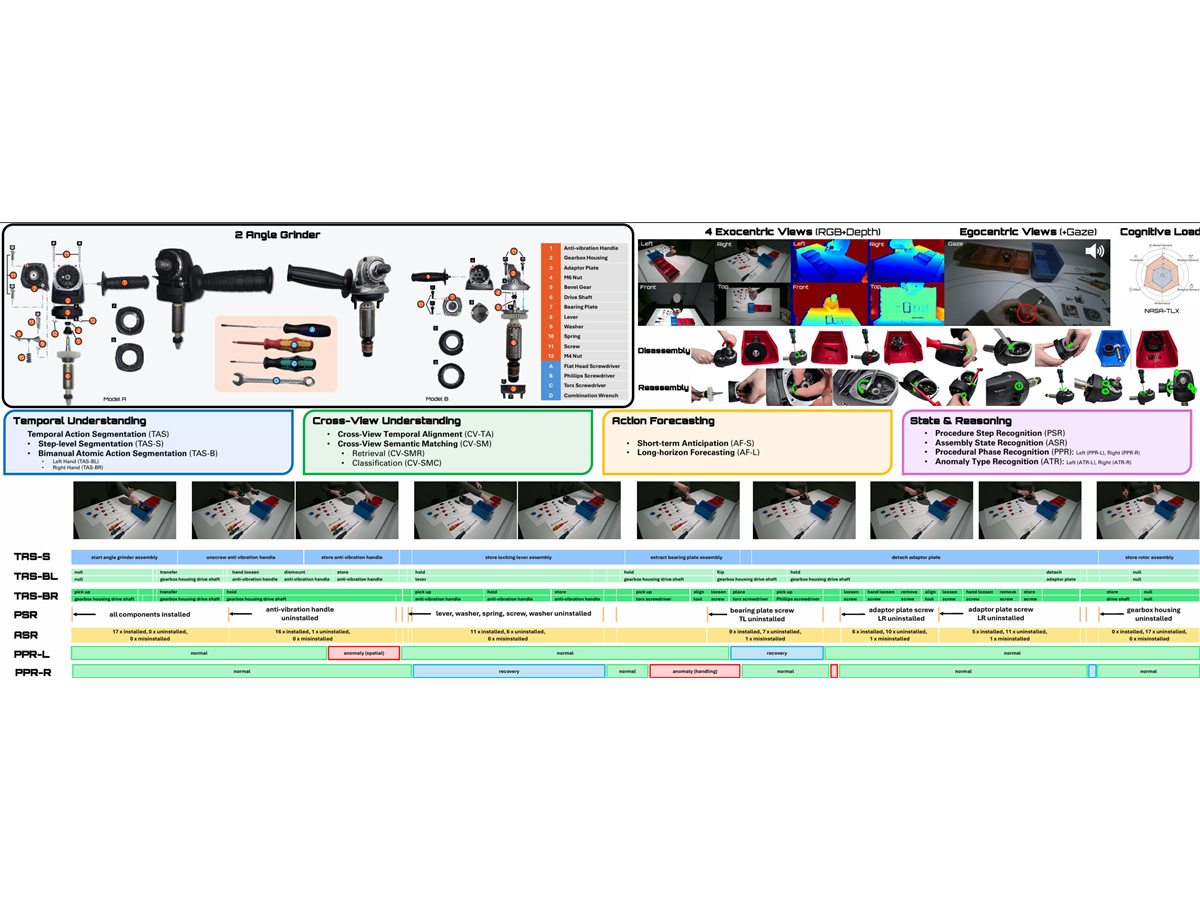
IMPACT: A Dataset for Multi-Granularity Human Procedural Action Understanding in Industrial Assembly
Multi-granularity procedural action understanding in industrial assembly.
Research Output
Selected and full publication record across visual understanding, multimodal perception, robust learning, datasets, and emerging embodied or real-world AI. Citation counts are best viewed on Google Scholar.
Selected
arXiv 2026
Multi-granularity procedural action understanding in industrial assembly.
Archive